Modeling a Constant-Compute Automated AI R&D Process
We’d like to know how much limits on compute scaling will constrain AI R&D. This post doesn’t have answers, but it does attempt to clarify thinking about how to use economic models to explore the question.
The Standard Model of Idea Production
A general “Jones-style” model of idea production1 is
$$\frac{d}{dt}A=A(t)^{1-\beta}K(t)^{\omega}L(t)^{\lambda}$$
- $A$ is total stock of ideas which have been found within a field
- $K$ is capital (for our purposes, this is physical compute)
- $L$ is researcher hours
The Greek letter parameters are assumed to be constant and nonnegative, and they describe how idea production responds to changes in $A$, $K$, and $L$.

You may want to refer to this image multiple times while you read
We’re interested in applying this model once physical compute scaling is done, which makes $K(t)^\omega$ a constant.2
The assumption that the exponent on $A(t)$ is at most one ($\beta \ge 0$) is downstream from the idea that over time, as all the low-hanging fruit are picked, new ideas in a field become harder to find. The empirical data say that the so-called ‘standing on shoulders’3 effect is actually negative ($\beta\approx2$).4
As for researcher hours $L$, in standard fields this isn’t boosted by new discoveries like it is for AI R&D. The exponent is estimated to be somewhere around $\lambda\approx0.75$.5
We cannot be very confident in these numerical estimates, as there is no clean way to measure things like ‘idea stock’ and so econometrics resorts to a variety of clever indirect methods which wind up generating lots of different estimates without a lot of consistency.
The Automation Feedback Loop
AI has the potential to automate AI R&D. This creates a unique field to model, as in most fields increasing the idea stock $A$ doesn’t automatically make the researchers more effective.
AI researchers can also try to increase effective compute by developing more efficient algorithms.
So our updated model looks something like this:
$$\frac{d}{dt}A=A(t)^{1-\beta};(K(t)^{\omega}A(t)^{\phi});(L(t)^{\lambda}A(t)^{\gamma})$$
Here we multiply capital and researcher hours by terms representing how much they are effectively increased by more idea stock.6

Here’s an updated reference image — we’ll get to δ in a bit
Separating $\phi$ and $\gamma$ from $\beta$ clarifies the meaning of each parameter and maintains the convention that these numbers are positive. Here, $\beta$ measures how quickly finding new ideas gets more difficult, $\phi$ measures how much the idea stock increases effective compute for constant physical compute, and $\gamma$ measures how much the idea stock increases AI researcher effectiveness.
If researchers are all AIs running on compute and compute is constant, we can simplify by setting $\lambda\approx0$ as well (although there will be direct substitution happening where the number of artificial researchers of a certain capability level can be traded for more compute and vice versa, this will reach some kind of equilibrium).
So our simplified equation becomes this:
$$\frac{d}{dt}A=\delta A(t)^{1-\beta+\phi+\gamma}$$
… where we’ve collapsed all our constants into $\delta$.
Well, now it’s easy to see that the question “Will there be a Software Intelligence Explosion” is roughly equivalent to asking if $1-\beta+\phi+\gamma \geq 1$ will be true.7
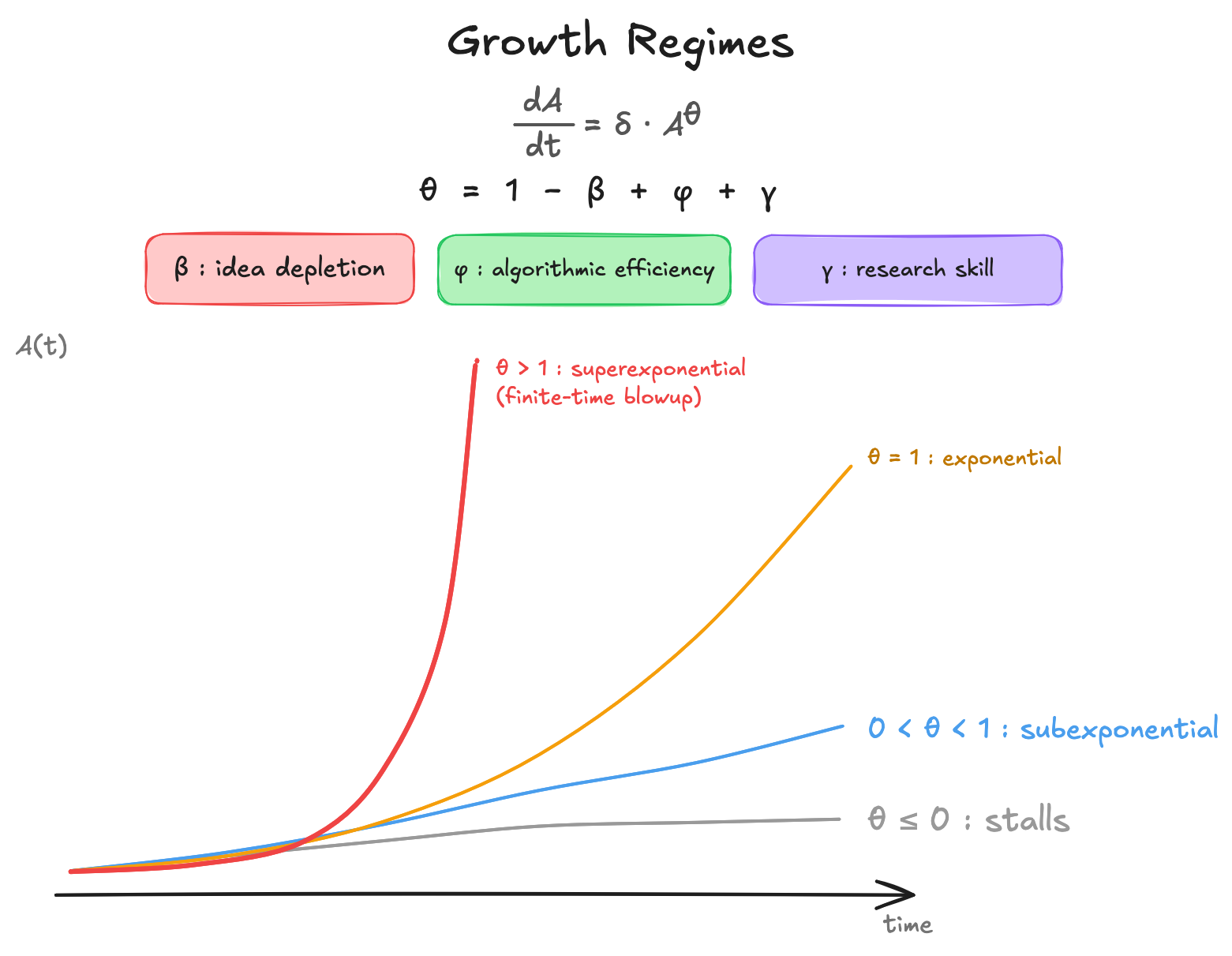
While the model usually assumes parameters are constant, we can expect $\phi$ to drop as we approach the theoretical limit of our physical compute. However, if current AI systems are far from the theoretical limits of intelligence per unit of compute, it’s possible that if $\phi$ is high it could stay that way for a while.8
$\gamma$ is probably the most important unknown here. It’s not yet possible to measure this and we don’t have any historical analogues. It’s here that Erdil and Besiroglu have intuitions which differ most strongly from those of the AI Futures Project, for example.
Constant Elasticity of Substitution vs the Jones-style model
Previous discussions of compute bottlenecks by Epoch, Davidson, and Whitfill & Wu have framed this question using a CES (Constant Elasticity of Substitution) production function:
$$Y = (\alpha K^\rho + (1-\alpha) L^\rho)^{1/\rho}$$

Here $K$ is experimental compute, $L$ is cognitive labor, and $\rho$ controls whether they are substitutes (goods that can replace each other in consumption) or complements (goods that are consumed together). The debate then turns on the value of $\rho$, generally agreed to be negative, with smaller magnitudes meaning faster takeoffs: Epoch argues $\rho \approx -0.4$, Davidson argues $\rho$ is between $-0.2$ and $0$, and Whitfill & Wu get wildly different empirical estimates depending on whether “compute” means total research compute ($\rho \approx 0.6$, positive!9) or frontier experiment scale ($\rho \to -\infty$).
We can and should think carefully about how to interpret this empirical instability of $\rho$, but it’s also worth looking beyond CES.10
The question of whether there will be a software intelligence explosion is a question about whether a dynamic feedback loop causes accelerating growth over time. But CES is static: it describes how contemporaneous inputs combine into contemporaneous output within a given period.
Even if Epoch is right that $\rho < 0$ and you cannot speed up R&D much by throwing more cognitive labor at fixed compute in a single period, that doesn’t settle the question of whether the accumulating stock of ideas (i.e. algorithmic improvements) make your fixed inputs more productive across time.
This means we need Jones-style ODE like above. CES and Jones are not alternatives to each other: You could put a CES inside a Jones-style model as the within-period aggregator of $K$ and $L$. CES by itself doesn’t represent the feedback from accumulated ideas into future productivity, which is where the explosion question lives.
My Takeaways
- It’s important to think not just about whether AI can autonomously increase the effectiveness of AI researchers, but also about how large this increase will be ($\gamma$).
- In traditional models of idea production, the exponent on $A$ is much lower than we should expect it to be in AI R&D. The feedback loops involved mean that traditional assumptions won’t necessarily hold.
- If a software intelligence explosion does happen we’ll be seeing some historically large production model parameters.
Thanks to economist Peter Pedroni for a long conversation which clarified my understanding of this. Thanks to @JustisMills, @apolloandersen, and @Tom Davidson for comments on drafts of this post.
This model is due to Charles “Chad” Irving Jones. A simplified version of this which ignores capital is called the Jones Model.
This model is also applicable as compute continues to scale. However, applying it in that context would require modeling a separate production function for compute. There’s no closed-form solution for this case, and it’s not a crux for determining ASI timelines in the same way as the constant-compute case.
A term coined by Jones; see page 1071 of this book chapter for his explanation of the term and the contrasting “fishing out” effect.
See Ma & Samaniego (2020). Macroeconomic shocks and productivity: Evidence from an estimated Ideas’ production function, page 4.
See the appendix of Are Ideas Getting Harder to Find?
Notably, I am modeling feedback from ideas into the productivity of compute and labor, but not the reverse channels, like how more compute might enable qualitatively new experiments that open up new idea-space.
Again: $\beta$ measures how quickly finding new ideas gets more difficult, $\phi$ measures how much the idea stock increases effective compute for constant physical compute, $\gamma$ measures how much the idea stock increases AI researcher effectiveness.
It seems like it’s currently high! See Epoch’s “Algorithmic progress in language models”
Positive $\rho$ means extra labor can make up for arbitrary losses in compute.
Peter Pedroni: “I agree … completely that the CES production function is not appropriate.”
